With the recent buzz about Elo rankings in tennis, both at FiveThirtyEight and here at Tennis Abstract, comes the ability to forecast the results of tennis matches. It’s not far fetched to ask yourself, which of these different models perform better and, even more interesting, how they fare compared to other ‘models’, such as the ATP ranking system or betting markets.
For this, admittedly limited, investigation, we collected the (implied) forecasts of five models, that is, FiveThirtyEight, Tennis Abstract, Riles, the official ATP rankings, and the Pinnacle betting market for the US Open 2016. The first three models are based on Elo. For inferring forecasts from the ATP ranking, we use a specific formula1 and for Pinnacle, which is one of the biggest tennis bookmakers, we calculate the implied probabilities based on the provided odds (minus the overround)2.
Next, we simply compare forecasts with reality for each model asking If player A was predicted to be the winner (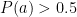
Model % correct Pinnacle 76.92% 538 75.21% TA 74.36% ATP 72.65% Riles 70.09%
What we see here is how many percent of the predictions were actually right. The betting model (based on the odds of Pinnacle) comes out on top followed by the Elo models of FiveThirtyEight and Tennis Abstract. Interestingly, the Elo model of Riles is outperformed by the predictions inferred from the ATP ranking. Since there are several parameters that can be used to tweak an Elo model, Riles may still have some room left for improvement.
However, just looking at the percentage of correctly called matches does not tell the whole story. In fact, there are more granular metrics to investigate the performance of a prediction model: Calibration, for instance, captures the ability of a model to provide forecast probabilities that are close to the true probabilities. In other words, in an ideal model, we want 70% forecasts to be true exactly in 70% of the cases. Resolution measures how much the forecasts differ from the overall average. The rationale here is, that just using the expected average values for forecasting will lead to a reasonably well-calibrated set of predictions, however, it will not be as useful as a method that manages the same calibration while taking current circumstances into account. In other words, the more extreme (and still correct) forecasts are, the better.
In the following table we categorize the set of predictions into bins of different probabilities and show how many percent of the predictions were correct per bin. This also enables us to calculate Calibration and Resolution measures for each model.
Model 50-59% 60-69% 70-79% 80-89% 90-100% Cal Res Brier 538 53% 61% 85% 80% 91% .003 .082 .171 TA 56% 75% 78% 74% 90% .003 .072 .182 Riles 56% 86% 81% 63% 67% .017 .056 .211 ATP 50% 73% 77% 84% 100% .003 .068 .185 Pinnacle 52% 91% 71% 77% 95% .015 .093 .172
As we can see, the predictions are not always perfectly in line with what the corresponding bin would suggest. Some of these deviations, for instance the fact that for the Riles model only 67% of the 90-100% forecasts were correct, can be explained by small sample size (only three in that case). However, there are still two interesting cases (marked in bold) where sample size is better and which raised my interest. Both the Riles and Pinnacle models seem to be strongly underconfident (statistically significant) with their 60-69% predictions. In other words, these probabilities should have been higher, because, in reality, these forecasts were actually true 86% and 91% percent of the times.3 For the betting aficionados, the fact that Pinnacle underestimates the favorites here may be really interesting, because it could reveal some value as punters would say. For the Riles model, this would maybe be a starting point to tweak the model.
In the last three columns Calibration (the lower the better), Resolution (the higher the better), and the Brier score (the lower the better) are shown. The Brier score combines Calibration and Resolution (and the uncertainty of the outcomes) into a single score for measuring the accuracy of predictions. The models of FiveThirtyEight and Pinnacle (for the used subset of data) essentially perform equally good. Then there is a slight gap until the model of Tennis Abstract and the ATP ranking model come in third and fourth, respectively. The Riles model performs worst in terms of both Calibration and Resolution, hence, ranking fifth in this analysis.
To conclude, I would like to show a common visual representation that is used to graphically display a set of predictions. The reliability diagram compares the observed rate of forecasts with the forecast probability (similar to the above table).

The closer one of the colored lines is to the black line, the more reliable the forecasts are. If the forecast lines are above the black line, it means that forecasts are underconfident, in the opposite case, forecasts are overconfident. Given that we only investigated one tournament and therefore had to work with a low sample size (117 predictions), the big swings in the graph are somewhat expected. Still, we can see that the model based on ATP rankings does a really good job in preventing overestimations even though it is known to be outperformed by Elo in terms of prediction accuracy.
To sum up, this analysis shows how different predictive models for tennis can be compared among each other in a meaningful way. Moreover, I hope I could exhibit some of the areas where a model is good and where it’s bad. Obviously, this investigation could go into much more detail by, for example, comparing the models in how well they do for different kinds of players (e.g., based on ranking), different surfaces, etc. This is something I will spare for later. For now, I’ll try to get my sleeping patterns accustomed to the schedule of play for the Australian Open, and I hope, you can do the same.
—
Peter Wetz is a computer scientist interested in racket sports and data analytics based in Vienna, Austria.
Footnotes
1. 



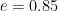
2. The betting market in itself is not really a model, that is, the goal of the bookmakers is simply to balance their book. This means that the odds, more or less, reflect the wisdom of the crowd, making it a very good predictor.
3. As an example, one instance, where Pinnacle was underconfident and all other models were more confident is the R32 encounter between Ivo Karlovic and Jared Donaldson. Pinnacle’s implied probability for Karlovic to win was 64%. The other models (except the also underconfident Riles model) gave 72% (ATP ranking), 75% (FiveThirtyEight), and 82% (Tennis Abstract). Turns out, Karlovic won in straight sets. One factor at play here might be that these were the US Open where more US citizens are likely to be confident about the US player Jared Donaldson and hence place a bet on him. As a consequence, to balance the book, Pinnacle will lower the odds on Donaldson, which results in higher odds (and a lower implied probability) for Karlovic.