I often illustrate the difference between Elo ratings and the traditional ATP and WTA ranking-point systems as follows: The official rankings tell you how good a player was six months ago. Elo estimates where they are today. For the purposes of tournament entry and so on, a 52-week average makes sense. But if you’re predicting the outcome of tomorrow’s match, you don’t want to assign the same weight to a year-old result that you give to yesterday’s news.
That said, Elo ratings are not explicitly predictive. They rely only on past results. They don’t recognize the fact that a player on a hot streak will probably cool off, or that a younger player is more likely to improve than an older one. If we want to look further ahead than tomorrow’s match, we need to take some of those additional factors into account.
Hence today’s project: Projecting Elo ratings one year in advance. Elo ratings tend to be a leading indicator of official rankings, so if we can get some idea of a player’s future in Elo terms, we can estimate–very approximately, I admit–his or her ATP or WTA ranking even further out.
I kept things simple. Each player’s forecast is based on four variables: Age, current Elo rating, rating one year ago, and rating two years ago. Current rating is by far the most important consideration. It accounts for over 70% of the men’s forecast and 80% of the women’s. Everything else is essentially a tweak. The two older ratings allow the forecast to make adjustments if the current rating is an outlier. By including player age, we account for the fact that players over 25 or 26 start–on average!–to decline, and the older they are, the sharper the decline.
Take Novak Djokovic as an example. His current Elo rating is 2,227, one year ago it was 2,145, and two years ago it was 2,186. Because his 2023 year-end rating was higher than 2021 or 2022, we’d expect a small step backwards. And because he’s 36 years old, the laws of physics might eventually slow him down. Put it all together, and the model projects his 2024 year-end Elo at 2,116. Excellent, but slightly more human, and a number that would’ve placed him third on this year’s list.
Here is what the model predicts as the 2024 year-end top ten:
Rank Player 2024 Elo 2023 Rank 2023 Elo 1 Jannik Sinner 2144 2 2197 2 Carlos Alcaraz 2137 3 2149 3 Novak Djokovic 2116 1 2227 4 Daniil Medvedev 2059 4 2104 5 Alexander Zverev 2021 5 2024 6 Andrey Rublev 1988 6 2020 7 Stefanos Tsitsipas 1969 9 1974 8 Holger Rune 1954 12 1936 9 Hubert Hurkacz 1950 8 1983 10 Grigor Dimitrov 1928 7 2011
As precise as that table looks, it is hard to predict the future. Here are the same ten players, with a 95% prediction interval shown:
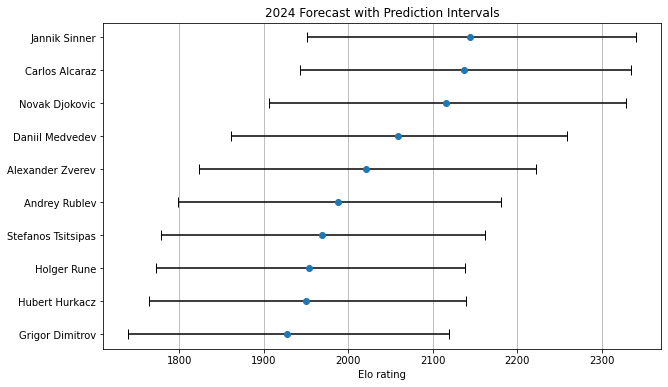
The intervals demonstrate just how uncertain we are, with 12 months of tennis to play. If Jannik Sinner or Carlos Alcaraz hits the high end of his range, in the mid-2,300s, he’ll have established himself as a runaway number one. But if they surprise in the other direction, they’ll land below 2,000 and just barely stay in the top ten. Even these intervals don’t quite account for all the unknowns. There’s a nonzero chance that any of these guys will get hurt and miss most of the season, leaving them off the 2024 year-end list entirely.
I suspect, also, that a more sophisticated model would give a different range of outcomes for Djokovic. There are few precedents for his level of play at age 36, and he outperformed expectations in 2023. Had we run this model a year ago, it would’ve predicted a 2,071 Elo for him now. He beat that by more than 150 points, landing around the 85th percentile of the projection. But time is cruel. Since 1980, five out of six 36-year-olds have seen their Elo decline from the previous season. The average year-over-year change–including those few players who gained–is a loss of 45 points. It’s hard to bet against Djokovic, but at this point in his career, his downside almost certainly exceeds his upside.
Finally, let’s take a look at the projected 2024 top ten on the women’s side. It’s not nearly as juicy as the men’s forecast, as it barely differs from the 2023 list. As I mentioned above, a player’s current rating is a bigger factor in the forecast than it is for men–age is less of a factor, and if a player’s rating jumps around from year to year, women are more likely to stay at their current level than bounce back to a previous one. The forecast:
Rank Player 2024 Elo 2023 Rank 2023 Elo 1 Iga Swiatek 2197 1 2237 2 Cori Gauff 2100 2 2127 3 Aryna Sabalenka 2062 3 2099 4 Jessica Pegula 2035 4 2089 5 Elena Rybakina 2024 5 2059 6 Marketa Vondrousova 1977 8 2005 7 Ons Jabeur 1976 7 2007 8 Karolina Muchova 1965 6 2014 9 Qinwen Zheng 1961 9 2000 10 Liudmila Samsonova 1938 11 1959
You might have noticed in both the ATP and WTA lists that most ratings–at least for top-tenners–are projected to go down. There’s a small regression component in the model, meaning that every player is expected to pull a bit back toward the middle of the pack. That doesn’t mean they will, of course, but on average, that’s what happens.
Here are the prediction intervals for the women’s top ten:
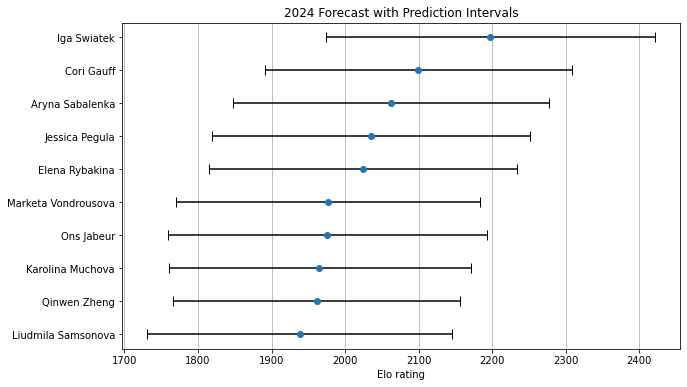
The magnitude of the intervals is about the same as it was for the men. Iga Swiatek could launch into a peak-Serena-like stratosphere, or she could, conceivably, land at the fringes of the top ten. Liudmila Samsonova, bringing up the end of this list, might challenge for a place in the top three, or she could be scrambling to stay in the top 50.
One thing is certain: The 2024 year-end lists won’t actually look like this. The value of this sort of forecast, even when it is so approximate, lies in the context it gives us. A year from now, we’ll be talking about which players outperformed or underperformed their expectations. Projections like these help us pin down what, exactly, was a reasonable expectation in the first place.
* * *
I’ll be writing more about analytics and present-day tennis in 2024. Subscribe to the blog to receive each new post by email:

