This is a guest post by Wiley Schubert Reed.
This week, the Memphis Open features the three tallest players ever to play professional tennis: 6-foot-10″ John Isner, 6-foot-11″ Ivo Karlovic, and 6-foot-11″ Reilly Opelka. And while these three certainly stand out among all players in the sport, they are by no means the only giants in the game. Also in the Memphis draw: 6-foot-5″ Dustin Brown, 6-foot-6″ Sam Querrey, and 6-foot-8″ Kevin Anderson. (Brown withdrew due to injury, and with Opelka’s second-round loss yesterday, Isner and Karlovic are the only giants remaining in the field.)
https://www.instagram.com/p/BQjI1gJBKgE/
There is no denying that the players on the ATP and WTA tours are taller than the ones who were competing 25 years ago. The takeover by the tall has been obvious for some time in the men’s game, and it’s extended to near the very top of the women’s game as well. But despite alarms raised about the unbeatable giants among men, the merely tall men have held on to control of the game.
The main reason: The elegant symmetry at the game’s heart. The tallest players have an edge on serve, but that’s just half of tennis. And on the return, extreme height–at least for the men–turns out to be a big disadvantage. But a rising crop of tall men have shown promise beyond their service games. If one of the tallest young stars is going to challenge the likes of Novak Djokovic and Andy Murray, he’ll have to do it by trying to return serve like them, too.
Sorting out exactly how much height helps a player is a complicated thing. Just looking at the top 100 pros, for instance, makes the state of things look like a blowout win in favor of the tall. The median top-100 man is nearly an inch taller today than in 1990, and the average top-100 woman is 1.5 inches taller [1]. The number of extremely tall players in the top 100 has gone up, too:
1990 Aug 2016
Top 100 Men Median Height 6-ft-0.0 6-ft-0.8
At least 6-ft-5 3% 16%
Top 100 Women Median Height 5-ft-6.9 5-ft-8.5
At least 6-ft 8% 9%
Height is clearly a competitive advantage, as taller young players rise faster through the rankings than their shorter peers. Among the top 100 juniors each year from 2000 to 2009 [2], the tallest players (6-foot-5 and over for men and 6-foot and over for women) [3] typically sit in the middle of the rankings. But they do better as pros: They were ranked on average approximately 127 spots higher than shorter players their age after four years for men and approximately 113 spots higher after four years for women.


Thus, juniors who are very tall have the best chance to build a solid pro career. But does that advantage hold within the top 100 of the pro rankings? Are the tallest pros the highest ranked?
For the women, they clearly are. From 1985 to 2016, the median top 10 woman was 1.2 inches taller than the median player ranked between No. 11 and No. 100, and the tallest women are winning an outsize portion of titles, with women 6-foot and taller winning 15.0 percent of Grand Slams, while making up only 6.6 percent of the top 100 over the same period. Most of these wins were by Lindsay Davenport, Venus Williams and Maria Sharapova. Garbiñe Muguruza became the latest 6-foot women’s champ at the French Open last year [4].
It’s a different story for the men, however. From 1985 to 2016, the median height of both the top 10 men and men ranked No. 11 to No. 100 was the same: 6-foot-0.8. And in those same 32 years, only three Grand Slam titles (2.4 percent) were won by players 6-foot-5 or taller (one each by Richard Krajicek, Juan Martin del Potro and Marin Cilic), while over the same period, players 6-foot-5 and above made up 7.7 percent of the top 100. In short, the tallest women are overperforming, while the tallest men are underperforming.
Why have all the big men accomplished so little collectively? One big reason is that whatever edge the tallest men gain in serving is cancelled out by their disadvantage when returning serve. I compared total points played by top-100 pros since 2011, and found that while players 6-foot-5 and over have a clear service advantage and return disadvantage, their height doesn’t seem to have a major impact on overall points won:
Height % Svc Pts Won % Ret Pts Won % Tot Pts Won
6-ft-5 and above 66.8% 35.7% 51.2%
6-ft-1 to 6-ft-4 64.5% 37.8% 51.1%
6-ft-0 and below 62.3% 39.1% 51.1%
Taller players serve better for two reasons. First, their height lets them serve at a sharper angle by changing the geometry of the court. With a sharper angle available to them, they have a greater margin for error to clear the top of the net while still getting the ball to bounce on or inside the service line. And a sharper angle also makes the ball bounce higher, up and out of returners’ strike zone [5].

Disregarding spin, for a 6-foot player to serve the ball at 120 miles per hour at the same angle as a 6-foot-5 player, he would need to stand more than 3 feet inside the baseline.
Second, a taller player’s longer serving arm allows him to whip the ball faster. For you physics fans, the torque (in this case magnitude of force imparted on the ball) is directly proportional to the radius of the lever arm (in this case the server’s extended arm and racket). As radius (arm length) increases, so does torque. There is no way for shorter players to make up this advantage. Six-foot-8 Kevin Anderson, current No. 74 in the world and one of the tallest players ever to make the top 10, told me, “I always say it’ll be easier for me to move like Djokovic than it will be for Djokovic to serve like me.”
One would think that height could be an advantage on return as well, with increased wingspan offering greater reach. 18-year-old, 6-foot-11 Reilly Opelka, who is already as tall as the tour’s reigning giant Ivo Karlovic and who ESPN commentator Brad Gilbert said will be “for sure the biggest ever,” told me his height gives him longer leverage. “My reach is a lot longer than a normal tennis player, so I’m able to cover a couple extra inches, which is pretty huge in tennis.”
But Gilbert and Tennis Channel commentator Justin Gimelstob said they believe tall players struggle on return because their higher center of gravity hurts their movement. If a very tall man can learn to move like the merely tall players that have long dominated the sport––Djokovic, Murray (6-foot-3), Roger Federer (6-foot-1) and Rafael Nadal (6-foot-1)–– Gilbert thinks he could be hard to stop. “If you’re 6-foot-6 and are able to move like that, I can easily see that size dominating,” he said.
Interestingly, Gilbert pointed out that some of the best returners in the women’s game––such as Victoria Azarenka (6-foot-0) and Maria Sharapova (6-foot-2)––are among its tallest players [6]. Carl Bialik asked three American women — 5-foot-11 Julia Boserup, 5-foot-10 Jennifer Brady and 5-foot-4 Sachia Vickery — why they think taller women aren’t at a disadvantage on return. They cited two main reasons: 1) Women are returning women’s serves, which are slower and have less spin, on average, than men’s serves, so they have more time to make up for any difficulty in movement; and 2) Women play on the same size court that men do, but a height that’s relatively tall for a woman is about average for men, and it’s a height that works well for returning, no matter your gender.
“On the women’s side, we don’t really have anyone who’s almost 6-foot-11 or 7-foot tall,” Brady said. While she’s above average height on the women’s tour, “I’m not as tall as Reilly Opelka,” she said.
Another reason players as tall as Opelka tend to struggle on return could be that they focus more in practice on improving their service game, which exacerbates the serve-oriented skew of their games. “Being tall helps with the serve and you maybe tend to focus on your serve games even more,” Karlovic, the tallest top 100 player at 6-foot-11 [7], said in an interview conducted on my behalf by members of the ATP World Tour PR & Marketing staff at the Bucharest tournament in April. “Shorter players aren’t as strong at serve so they work their return more.”
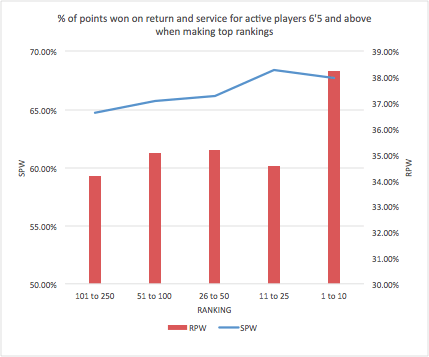
Charting the careers of all active male players 6-foot-5 and above who at some point ranked year-end top 100 bears this out. Their percentage of service points won increased by about 6 percentage points over their first eight years on tour [8], while percentage of return points won only increased by about 1.5 percentage points. In contrast, Novak Djokovic has steadily improved his return points won from 36.7 percent in 2005 to 43.9 percent in 2016.
When very tall men break through, it’s usually because of strong performance on return: del Potro and Cilic, who are both 6-foot-6, boosted their return performances to win the US Open in 2009 and 2014, respectively. At the 2009 US Open, del Potro won 44 percent of return points, up from his 40 percent rate on the whole year, including the Open. At the 2014 US Open, Cilic won 41 percent of return points, up from 38 percent that year. And they didn’t improve their return games by facing easy slates of opponents: Each man improved on his return-point winning rates against those same opponents over his career by about the same amount as he elevated his return game compared to the season as a whole.
“It’s a different type of pressure when you’re playing a big server who is putting pressure on you on both the serve and the return,” Gimelstob said. “That’s what Cilic was doing when he won the US Open. That’s the challenge of playing del Potro because he hits the ball so well, but obviously serves so well, also.” To put things into perspective, if del Potro and Cilic had returned at these levels across 2016, each would have ranked among the top seven returners in the game, joining Djokovic, Nadal, Murray, 5-foot-11 David Goffin, and 5-foot-9 David Ferrer. Neither man, though, has been able to return to a Slam final; del Potro has struggled with injury and Cilic with inconsistency.
For the tallest players, return performance is the difference between making the top 50 and the top 10. On average, active players 6-foot-5 and above who finished a year ranked in the top 10 won 67.7 percent of service points that year, while those who finished a year ranked 11 through 50 won 68.1 percent of service points, on average. That’s a difference of only 0.4 percentage points. The difference in return performance between merely making the top 50 and reaching the top 10, however, is far more striking: Tall players who made the top 10 win return points at a rate nearly 4 percentage points higher than do players ranked 11 through 50.

A solid-serving player 6-foot-5 or taller who can consistently win more than 38 percent of points on return has an excellent chance of making the top 10. Tomas Berdych and del Potro have done it, and Milos Raonic is approaching that mark, one reason he reached his first major final this year at Wimbledon. Today there are several tall young men who look like they could eventually win 38 percent of return points or better. Alexander Zverev (ranked 18) and Karen Khachanov (ranked 48) are both 6-foot-6, each won about 38 percent of return points in 2016, and neither is older than 20. Khachanov has impressed Gilbert and Karlovic. “That guy moves tremendous for 6-foot-6,” Gilbert said.
Other giants have impressed recently. Jiri Vesely, who is 23 and 6-foot-6, beat Novak Djokovic last year in Monte Carlo and won nearly 36 percent of return points in 2016. Opelka reached his first tour-level semifinal, in Atlanta. Most of the top 10 seeds at Wimbledon lost to players 6-foot-5 or taller. Del Potro won Olympic silver, beating Djokovic and Nadal along the way.
But moving from the top 10 to the top 1 or 2 is another question. Can a taller tennis player develop the skills to move as well as the top shorter players, and win multiple major titles? Well, it’s happened in basketball. “We haven’t had a big guy play tennis that’s like 6-foot-6, 6-foot-7, 6-foot-8, that’s moved like an NBA guy,” Gilbert said. “When you get that, that’s when you get a multiple Slam winner.” Anderson agrees that height is not the obstacle to movement people play it up to be: “You know, LeBron is 6-foot-8. If he can move as well as somebody who’s 5-foot-10, his size now is a huge advantage; there’s not a negative to it.”
Opelka, who qualified for his first grand slam main draw at the 2017 Australian Open where he pushed 11th-ranked David Goffin to five sets, says he is specifically focusing on the return part of his game in practice. “I’ve been spending a ton of time working on my return. When you look at the drills I’m doing in the gym, they work on explosive movement.” But he also points out that basketball players “move better than [tennis players] and are more explosive than [tennis players]” because of their incredible muscle mass, which won’t work for tennis. “I don’t know how they’d be able to keep up for four or five hours with that mass and muscle.” Put LeBron on Arthur Ashe Stadium at the U.S. Open in 100 degree heat for an afternoon, “it’s tough to say how they’ll compare.”
Zverev, who is 19 and 6-foot-6, agrees that tall tennis players face unique challenges: “Movement is much more difficult, and I think building your body is more difficult as well.” But the people I talked to believe that both Opelka and Zverev could be at the top of the game in a few years’ time. “Zverev––that guy could be No. 1 in the world,” Gilbert said. “He serves great, he returns great and he moves great.” And as for Opelka, Gilbert says: “Right now he’s got a monster serve. If he can develop movement, or a return game, who knows where he could go?”
Whether the tallest guys can develop the skills to consistently return at the level of a Djokovic or a Murray remains to be seen. But starting out with a huge serve is a major step toward eventually challenging them. As Opelka says, “every inch is important.”
Wiley Schubert Reed is a junior tennis player and fan who has written about tennis for fivethirtyeight.com. He is a senior at the United Nations International School in New York and will be entering Harvard University in the fall.
Continue reading Are Taller Players the Future of Tennis?







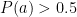 ), did he really win the match? When we do that for each match and each model (ignoring retirements or walkovers) we come up with the following results.
), did he really win the match? When we do that for each match and each model (ignoring retirements or walkovers) we come up with the following results.
 where
where  are player A’s ranking points,
are player A’s ranking points,  are player B’s ranking points, and
are player B’s ranking points, and  is a constant. We use
is a constant. We use 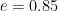 for ATP men’s singles.
for ATP men’s singles.


